In August 2025, OpenAI introduced two downloadable open-weight models, gpt-oss-120b and gpt-oss-20b, that you can run on your hardware or inside your cloud. The 120b variant is engineered to run on a single 80 GB GPU (e.g., H100/MI300X) thanks to native MXFP4 quantization. In contrast, the 20b is tuned to fit in roughly 16 GB of GPU memory—making local or self-hosted inference practical for far more teams.
That single move changed the tone around local, portable AI. ‘Download it and run it yourself’ isn’t a weekend experiment anymore; it’s a practical way to ship production features.
Meanwhile, on-device computing also advanced significantly. Microsoft’s Copilot+ PC baseline puts NPUs around 45 TOPS, and Qualcomm’s newly announced Snapdragon X2 Elite/Extreme pushes that to about 80 TOPS in the new wave of AI PCs. Practically, many day-to-day inference tasks now run locally with acceptable latency and battery life; you only burst to the cloud when you truly need to.
However, portability alone doesn’t guarantee trust. The models are easier to run, but how you expose them—fairly, safely, audibly, etc.—still requires improvement. This piece is a simple map of the domain: what “open-weight” actually means, why open access via permissionless APIs is useful, and how to meter usage with clear budgets, quotas, and receipts. We’ll use Pocket Network sparingly as a real-world example of the open access and metering layer, and we’ll pair it with other examples so you can see the whole field.
What Open-weight Means
Open-weight means the trained parameters (called weights) of an LLM are shareable and published for you to download and run. You can, within the model’s license, serve the model, fine-tune it, quantize it, and even redistribute its derivatives.
It is not the same as “open source” under OSI rules, which generally requires more than just final code. OSI’s Open Source AI Definition 1.0 says that to be open source AI, you must have the preferred form to modify the system, i.e., data transparency and training code, not just final tensors.
“Model weights are the learned numerical parameters of an AI model—millions or billions of values tuned during training that capture the knowledge the model extracts from its data. Think of them as adjustable “knobs” that control how inputs are combined and transformed through the network; together, they determine how the model processes data and produces outputs, i.e., its behavior.”
Definition Summary
| Term | What you get | What you don’t necessarily get | Typical examples |
| Closed model (hosted) | An API and ToS; usage-based billing; vendor rate limits | Weights, reproducibility, flexible infra | DALL·E via API (and successors), most frontier models. |
| Open-weight | Downloadable weights (often permissive license), local or self-hosted inference, fine-tuning | Full training data; OSI-compliant “open source” terms | OpenAI GPT-OSS, Mistral Mixtral |
| Open source (per OSI) | All the freedoms: use, study, modify, share (including training data transparency under OSI’s AI definition) | — | Rare today for frontier-class LLMs; OSI states that Llama is not open-source. |
What you actually get
- Downloadable weights you can run locally or in your own cloud,
- Compatibility with common servers (vLLM/TGI/Ollama) and standard APIs,
- Freedom to fine-tune/quantize (subject to the license),
- Portability across vendors and hardware.
What you usually don’t get
- Original training data and full pre-training pipeline,
- Full data lineage/provenance and reproducible training scripts,
- An OSI-compliant license (varies by model family),
- Unrestricted redistribution (check the license terms).
Examples of Open-Weight Models
| Model (family) | License | Sizes/VRAM target | Typical use |
| OpenAI GPT-OSS (20B/120B) | Apache-2.0 | ~16 GB (20B), ~80 GB (120B), 128k ctx | General LLM baseline you can download and serve today; broad distro (HF/Azure/AWS/Databricks/vLLM/Ollama). Link |
| Meta Llama 3.1 (8B/70B/405B) | Llama Community License | 8B – 16 GB; 70B/405B multi-GPU/cluster | Versatile fine-tune target; large ecosystem. Link |
| DeepSeek-R1 (reasoning, 1.5B→70B) | MIT | Varies by size | Reasoning-focused open weights; multiple distilled checkpoints. Link |
| DeepSeek-V3 (MoE, 671B / ~37B active) | DeepSeek Model License (commercial allowed) | Cluster-class; FP8/BF16 | High-performance MoE; strong open-weight contender. (Link) |
| Mistral Mixtral 8×7B | Apache-2.0 | Multi-GPU; efficient MoE | Cost/perf workhorse; widely supported in vLLM/TGI. Link |
| Qwen 2.5 (0.5B→72B; VL variants) | Mostly Apache-2.0; 3B/72B under Qwen license | 7B fits 16 GB-class; 72B multi-GPU | Multilingual/text-+-vision family; strong tools/coding. Link |
| Google Gemma 2 (9B / 27B) | Gemma Terms (open weights with use terms) | Lightweight; on-prem or Vertex | Compact text models for local or cloud. Link |
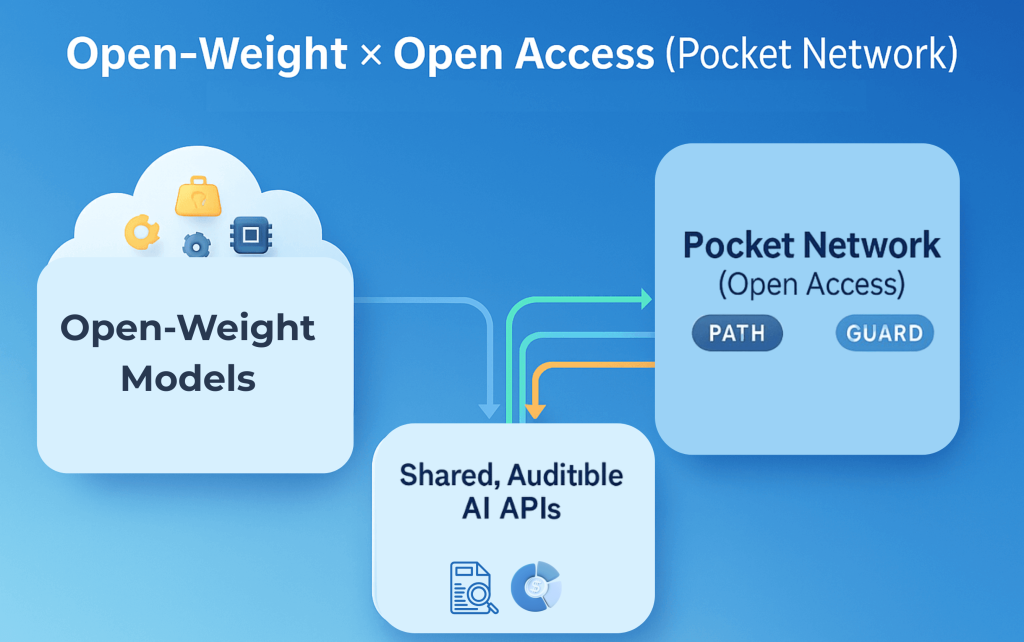
Where Open-Weight Meets Open Access
The idea: Open-weight makes AI portable; open access (permissionless gateways) makes that portability usable and trustworthy across teams, customers, and communities.
Open-weight gives you the artifact (downloadable weights) and the right to run or fine-tune them. That’s freedom, but it’s local. The moment you want to share those models across products, orgs, classrooms, or a public API, you need a control plane: keys, quotas, routing, and a single place to meter usage. That’s what open access supplies. Make the gateway permissionless and the receipts neutral, and you’ve closed the trust gap: anyone can operate/consume the service, and everyone can verify what happened.
Why open-weight needs open access
- From “can run” to “can share.” Weights let you run a model; gateways let others use it safely without handing over infrastructure.
- From portability to predictability. Portability is pointless if budgets are unsustainable; metering (tokens/ms/, or CUs) and per-key quotas help keep costs in check.
- From logs to receipts. In multi-party settings (such as customer, grant, and DAO), CSVs are insufficient. Append-only receipts—ideally on a neutral/public ledger—turn billing into reconciliation, not debate.
- From a single vendor to many operators. A permissionless gateway pattern means operators can come and go without breaking the client contract.
Design principles for a permissionless control plane
- Model-agnostic interface. The same API is used whether the backend is GPT-OSS, Mixtral, or SDXL.
- Budget first. Enforce per-key ceilings and fair sharing before scale, not after.
- Neutral receipts. Record {key, model, time, meter} to an append-only store; mirror to a public/neutral ledger when trust spans orgs.
- Operator plurality. Don’t anchor the service to a single operator; instead, allow multiple gateways/suppliers under the same contract.
- Graceful failure. When budgets deplete or backends fail, degrade (or queue), don’t crash.
Pocket Network in the Picture — What a Permissionless Gateway Really Is
On the protocol side, Pocket’s Shannon upgrade enables gateways to become permissionless through PATH (short for PATH API and Toolkit Harness), allowing them to stand up and settle on-chain, transitioning from a curated model to open, on-chain access for demand-side actors. That’s the “open access” half that pairs with open-weight portability.
Pocket Network anchors this Open Access by allowing anyone to operate a decentralized gateway that appears as a standard OpenAI-style HTTP API, while enforcing budgets and generating verifiable usage receipts onchain. The entry point is the PATH gateway, which terminates requests, validates them, and routes them to the correct backend. By default, it runs on port 3069 with a readiness endpoint at /healthz.
PATH supports header-based routing for local runs and subdomain-based routing in production-style URLs, where the service ID is derived from the subdomain. This keeps the client contract stable even as you swap models or add suppliers.
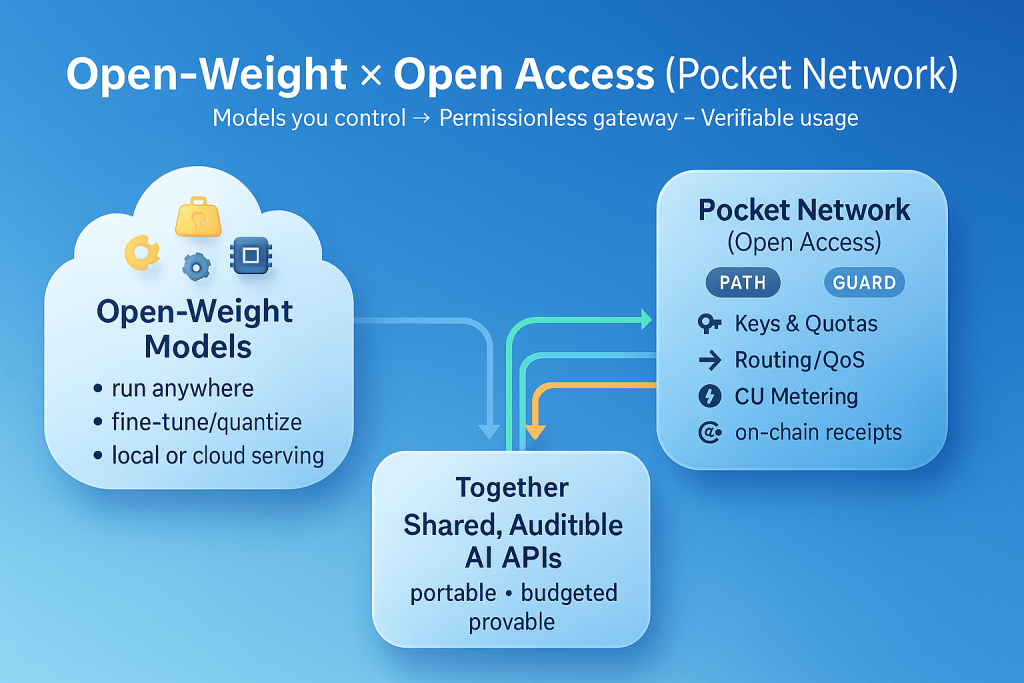
The Open-Access (Pocket Network) Bridge for Open-Weight AI
Inside Pocket Network’s Permissionless Gateways for Open Access
At the edge, the PATH and GUARD stack serve as your control plane. PATH terminates the API call; GUARD is the policy layer that issues/validates API keys, enforces per-key quotas and rate limits, and applies sensible request bounds (e.g., max tokens, timeouts, payload size) so one tenant can’t exhaust shared capacity.
“Under the hood, PATH is built around a few core components that work together to deliver reliable, permissionless API access.”
In practice, you can segment usage by team or product via keys, and steer traffic to specific services (e.g., a small reasoning model vs. a large one) using headers or subdomains—without changing client code.
Behind the gateway, suppliers perform the work: today, that’s blockchain RPC endpoints, but under Shannon, the supplier model is intentionally data-source agnostic, including things like LLM endpoints you host with vLLM/TGI/Ollama.
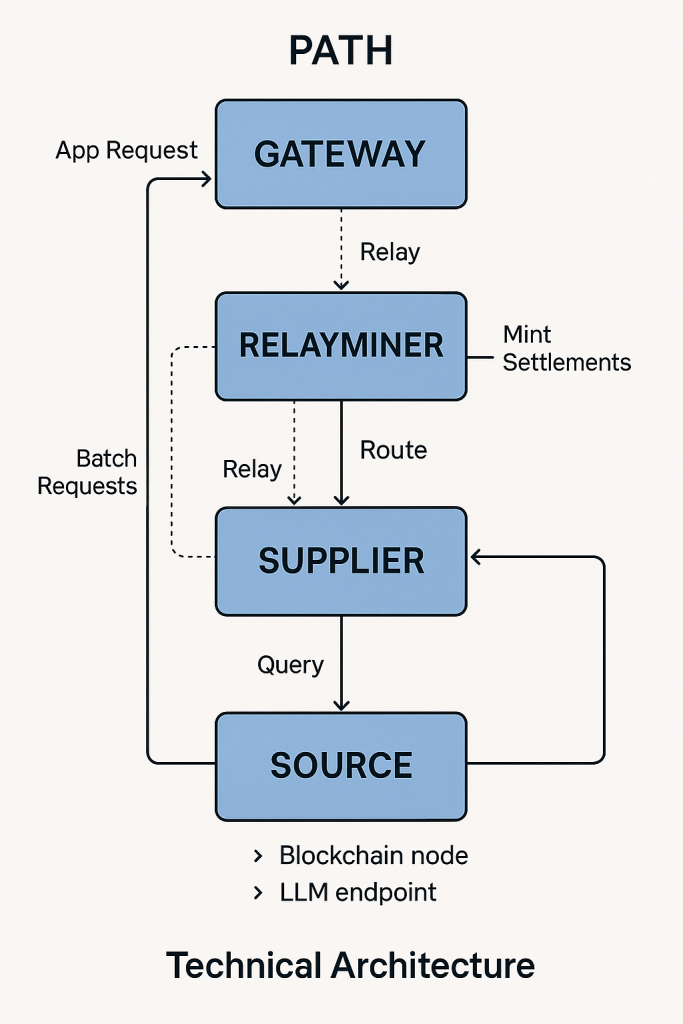
Technical Architecture of PATH
Economics, receipts, and QoS (how usage becomes trust)
Pocket Network meters usage in Compute Units (CUs), so pricing is model-agnostic and USD-pegged. The current price is $1 per 1,000,000,000 CUs (i.e., 1e-9 USD per CU), paid through the network’s native token—POKT. A Compute Unit-to-Token Multiplier (CUTTM) is used to adjust the peg and maintain stability as the POKT token price fluctuates, with a target of approximately $2.50 per million relays across the network.
Each accepted request is measured in CUs and recorded as a compact usage receipt, which is then anchored on-chain via burn/mint settlement, replacing vendor CSVs with a neutral, verifiable record of consumption. To bootstrap durable demand, a volume-rebate scheme is implemented, scaling from 10% to 40% between 105M and 525M relays per day equivalents, with a quarterly cap on total rebatable CUs. Multiple industry articles summarize this as part of Shannon’s launch.
Reliability is handled where it counts: PATH ships QoS-oriented checks and routing, along with Prometheus metrics (success/error/latency). For blockchain reads, the gateway layer includes “disqualified endpoint” hygiene and health checks. For model serving, the same primitives prevent unhealthy suppliers from poisoning the pool while respecting per-key budgets and rate limits.
Summary table of different pathways to serve your endpoints
| Access pattern | Portability | Cost control | Auditability | Trust model | Who it fits |
| Closed vendor API | Low | Medium (vendor plans) | Low (vendor CSVs) | Trust the vendor | Solo builders, quick prototypes |
| Self-hosted + private gateway | High | High | Medium (your logs) | Trust your ops | Single-org workloads |
| Permissionless gateway + receipts | High | High (per-key budgets) | High (neutral receipts) | Trust-minimized | Shared labs, DAOs, public APIs |
End-to-end flow (Open-Weight × Open Access)
- Spin up the open-weight model, e.g., an OpenAI-compatible endpoint: Launch your checkpoint (e.g., Llama/Mixtral/GPT-OSS) with vLLM’s OpenAI server, which exposes /v1 Chat/Completions so clients don’t need custom SDKs. This is the “model surface” to which you will connect the gateway. More info here
- Define the service contract that maps model work to CUs: Decide how you’ll measure model usage (tokens/ms) and set an initial compute_units_per_relay for the new service; this parameter lives in the service config and tells gateways how much CU to charge per call.
- Publish a Pocket “Service” (register your serviceId): Create the service on Shannon with your service ID and CU settings so that any permissionless gateway can consistently discover and meter it. This makes your model first-class in the network’s catalog, not a one-off URL.
- Run the edge—PATH (proxy) and GUARD (policy) to wire them to your model: Start PATH (default: 3069), verify readiness with a GET request to/healthz, and route to your model (Learn how to set up a PATH gateway here). For local calls, send requests to http://localhost:3069/v1 with the Target-Service-Id. In a hosted form, the service ID can be obtained from the subdomain (e.g., https://{serviceId}.rpc.grove.city); no header is needed. GUARD provides authentication, per-key quotas/rate limits, and routing policies—i.e., the access controls your open-weight API needs when used by multiple teams or the public—more info on GUARD here.
- Issue keys & budgets; expose a stable client contract: Create API keys in GUARD and set per-key budgets so that one tenant can’t exhaust the model. Whether clients access your service via a header (local) or subdomain (hosted), the URL contract remains the same, regardless of whether operators or backends change. More info here
- Send traffic and confirm metering: Make a test request to your PATH endpoint. In the gateway/miner logs (or the emitted receipt), verify that a CU value was recorded for the call and that the API key’s budget decreased. If CU is missing or incorrect, update compute_units_per_relay in your service configuration and retry.
- Settle and verify with neutral receipts (burn/mint): Each accepted call emits a compact receipt and is anchored on-chain via burn/mint, allowing partners, finance, or DAOs to verify usage independently, eliminating CSV trust games.
A Real World Example — A treasury rebalancing agent
Assumptions
- Company: Harbor DAO treasury team (mid-sized, public multisig).
- Models: DeepSeek-R1 32B for reasoning + GPT-OSS-20B for summaries (both open-weight, served locally via vLLM).
- Infra: one A6000 workstation (48 GB) for R1, one 24 GB box for GPT-OSS-20B; PATH + GUARD on a small VM in front.
- Users: 12 strategy bots (ETH/L2 pools) + 2 analysts; each gets its own API key.
- Budgeting: per-bot weekly caps (tokens → mapped to CUs) and a higher cap for the analyst keys.
- Why Pocket here: the DAO’s finance committee wants usage receipts that it can verify during monthly spend reviews.
The story
Maya, Harbor’s platform lead, ships a rebalancing agent that watches AMM pools and proposes trades when fees outweigh gas and slippage. She runs DeepSeek-R1 locally for the “should we rebalance?” reasoning step, and GPT-OSS-20B to draft short justifications for analysts. Both models sit behind PATH, so the bots and humans hit a single /v1 endpoint they already know.
GUARD issues a separate key for each bot and analyst and sets weekly budgets. When the “ARB-stables” bot has a noisy week and hammers the endpoint, it cleanly hits its cap and pauses; other strategies continue uninterrupted. On Friday, analyst Leo reviews the week’s proposals. He can reconcile total usage because each call produced a receipt (metered in compute units) that’s anchored on-chain—exactly what the finance committee wants when it signs off reimbursements from the treasury.
Two weeks in, Maya swaps the summary model from GPT-OSS-20B to a lighter Mixtral variant for speed. No bot code changes: PATH routes by service ID, and the client contract doesn’t move. Later, a new volunteer sets up extra capacity and runs another gateway; the bots continue to use the same URL, and the receipts remain verifiable regardless of who is supplying them.
Summary
- Open-weight gives Harbor control and privacy: models run on hardware they manage, prompts never leave their infra, and they can fine-tune if needed.
- Open access (Pocket Network’s permissionless gateway) makes that power usable across many actors: per-key budgets for 12 bots and two analysts, neutral CU metering, and receipts that the finance committee can verify without needing Maya’s spreadsheets.
Did you know?
Pocket Network can also serve as a data and inference layer: pull on-chain (and other) data through hosted PATH endpoints today, and when you’re ready, front your open-weight models with a permissionless PATH gateway—same rails for both (keys, quotas, CU metering, on-chain receipts).
Wrap-up
We started by grounding open-weight—downloadable weights you can run, fine-tune, and swap—and clarifying that it isn’t the same as OSI “open source.” With stronger on-device hardware, running your own models is practical; what you still need is open access —a permissionless control plane so that those models are safe to share and easy to account for.
That’s where the pairing clicks. Open access adds keys and quotas, model-agnostic metering (CUs), and verifiable receipts. We demonstrated how Pocket integrates seamlessly without overshadowing the story: PATH provides a familiar HTTP surface, GUARD enforces budgets and policies, CUs and CUTTM keep costs predictable, and burn/mint converts usage into receipts, backed by QoS and simple routing (header or subdomain). The end-to-end flow, along with the two examples (treasury agent and tiny signals shop), made it real, and we noted that Pocket Network can serve as both data and inference rails on the same stack.
Open-weight gives you portability and privacy; open access adds predictability and proof. Together, you get AI you can run—and that others can rely on. If you take one thing with you, let it be this: run the models you want, where you want—and expose them in a way others can rely on. That’s the union of open-weight and open access.
Want to go deeper?
- Spin up a PATH gateway and test budgets/quotas and receipts.
- Skim the Shannon economics explainer (CUs, CUTTM, rebates) and the PATH quickstart.
- Drop into the Pocket Network Discord to swap patterns and get help from operators.
- Revisit our guides and case studies when you’re ready to take a model from local to shared.
.