
This community contribution is intended to be an example implementation and may require additional configuration or environmental variables not mentioned here. This is not intended to be a definitive guide or best practices.To submit your own community contribution, please email hello@pocket.foundation.
AI is progressing faster than ever, but a few powerful corporations control most of its developments. Estimates show that just a handful of companies hold over 75% of AI patents and research funding.
This heavy concentration of influence raises concerns about accessibility, censorship, and monopolistic practices — potentially stifling innovation, creating biased algorithms, and limiting public access to advanced AI.
However, there is a beacon of hope; recent developments signal a shift away from centralized control, with emerging players like DeepSeek proving that high-performance AI can be developed outside corporate monoliths.
At the same time, Pocket Network enables decentralized AI inference, which means AI models can be accessed in a permissionless and censorship-resistant way. The decentralized AI market experienced a 200% increase in funding and user participation over the past year, reflecting a surge of interest in open and transparent AI development.This article will explore how to build a fully decentralized AI pipeline that uses Pocket Network for permissionless inference while using a decentralized infrastructure for compute, storage, and open-source model deployment. By distributing AI model training, inference, and data across a censorship-resistant network, this architecture eliminates reliance on centralized providers, ensuring greater accessibility, cost efficiency, and autonomy.
Drawbacks of Centralized AI For Developers
Companies like OpenAI, Google, and Anthropic have outsized control over AI access, deciding who can use their models, how they function, and at what price. They shape the AI landscape, making it harder for independent developers to compete and innovate. Here’s how that impacts the industry:
High Costs and Paywalls
Accessing large language models via API (such as OpenAI’s GPT models) can be expensive. Pricing scales with usage, making it difficult for startups and independent developers to afford continuous inference.
Censorship and Content Restrictions
Most AI providers enforce strict content policies. Certain topics or inquiries may be blocked entirely, limiting innovation and research applications.
Opaque Model Training and Bias
Closed-source AI models lack transparency in how they are trained. Developers have no insight into what data is used, how bias is mitigated, or whether certain perspectives are systematically excluded.
Cloud Dependence and Vendor Lock-in
Proprietary AI APIs are hosted on centralized cloud infrastructure (AWS, Google Cloud, Azure), meaning availability is at the provider’s discretion. If an organization is de-platformed, its AI application ceases to function.
Why Use Permissionless AI Infrastructure?
To address these issues, AI models should be:
- Open-Source: If anyone can inspect, modify, and use the models, transparency and collaboration can only increase.
- Deployed on Decentralized Infrastructure: Networks like Akash ensure access to computational resources without reliance on centralized providers.
- Stored in a Censorship-Resistant Manner: Using IPFS and Filecoin for distributed storage guarantees that model data remains accessible and tamper-proof.
- Queried via Decentralized Routing: Pocket Network provides a decentralized solution to handle AI queries, reducing single points of failure and enhancing resilience.
Decentralized AI Stack: The Key Components
Building a decentralized AI pipeline requires integrating multiple technologies that replace traditional cloud-based AI deployment. They include the compute Layer, Data Layer, and Inference Layer
1. Compute Layer: Running AI Models on Permissionless GPUs
AI models require high-performance GPUs for training and inference. Instead of relying on centralized cloud providers, developers can utilize decentralized marketplaces for GPU computing. These platforms allow users to lease GPU power permissionlessly, often transacting with cryptocurrency rather than signing an enterprise contract.
Example Platforms
- Render Network: Decentralized GPU rendering platform that harnesses idle GPU power worldwide, providing near-limitless capacity at a fraction of the usual cost.
- io.net: Developed for large-scale AI startups, io.net offers a decentralized GPU network delivering cost-efficient computing power to fuel innovation.
- Akash Network: Akash is a permissionless marketplace for decentralized cloud computing. It offers scalable and cost-efficient GPU rentals for AI workloads.
2. Data Layer: Censorship-Resistant Model Storage
AI models require long-term storage for their weights, configurations, and fine-tuned versions. Decentralized storage solutions like IPFS (InterPlanetary File System) and Filecoin allow AI models to be stored in a distributed manner, ensuring accessibility without reliance on a centralized cloud provider.
3. Inference Layer: Querying AI Models via Decentralized Routing
The inference layer is critical to any AI system, processing real-time queries and delivering AI-generated responses. When a user submits a prompt—whether it’s for text generation, image recognition, or data analysis—the inference layer ensures that the request is processed efficiently and returned with minimal latency.Most AI applications require real-time query capabilities, in which users send prompts and receive responses. Unlike centralized APIs, decentralized inference routing platforms like Pocket Network distribute queries across multiple inference nodes, eliminating single points of failure.
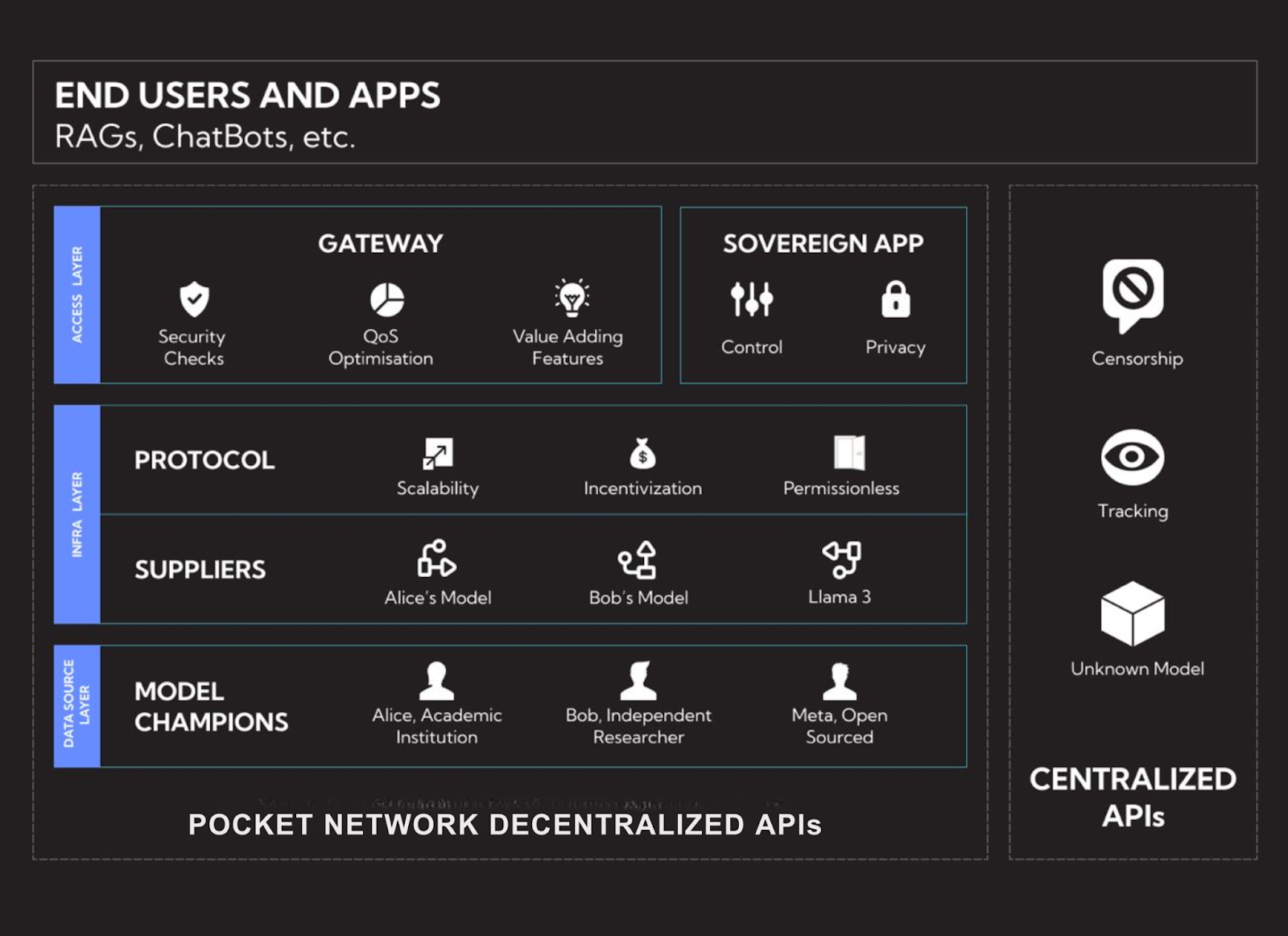
Pocket Network for Decentralized AI Inference
Pocket Network is pioneering a decentralized approach to AI inference, addressing the limitations of centralized systems by leveraging its established decentralized RPC infrastructure. Since its MainNet launch in 2020, Pocket Network has processed over 740 billion requests, demonstrating its capacity to handle large-scale operations.
Decentralized Framework and Stakeholder Alignment
The network’s open-source and permissionless design fosters collaboration among various stakeholders:
- Model Sources: AI researchers and engineers who develop models.
- Suppliers: Hardware operators providing computational resources.
- Gateways: API providers facilitating access to models.
- Applications: End-users integrating AI capabilities.
How Pocket Network Enables Decentralized AI Inference
The Shannon Upgrade, already in Beta TestNet, is transforming Pocket Network from a decentralized RPC provider into a permissionless AI inference network. This upgrade enables applications to query AI models in a censorship-resistant and cost-efficient manner, with cryptographically verifiable query routing. While Pocket ensures that AI requests are properly relayed and processed in a trustless environment, it does not enforce verifiability of model execution or outputs. Its framework for AI inference has three key components:
Relay Mining Algorithm: Proof of AI Work
Pocket Network’s Relay Mining algorithm cryptographically verifies network usage by tracking the number of inference requests serviced. This system ensures:
- Fair Compensation: AI inference providers are rewarded based on verifiable work.
- Network Integrity: Fraudulent service providers are filtered out on-chain.
- Scalability: New inference providers can join as demand grows.
Supplier Nodes: Powering AI Inference
Suppliers are responsible for running AI models and responding to queries. These can be:
- Standalone AI Inference Nodes: Operators running LLMs like DeepSeek on decentralized compute resources.
- Proxy Nodes: Nodes that route AI inference tasks across multiple GPUs, similar to how blockchain RPC providers distribute requests.
- Idle Compute Utilization: Pocket allows unused GPUs and TPUs to be repurposed for AI inference, lowering overall costs.
Gateways: The Interface Between Applications and AI Models
Instead of developers querying AI models directly, they interact with Gateways—a key component of Pocket Network’s AI inference stack. Gateways:
- Balance Workloads: Dynamically route AI requests to the most available and efficient inference nodes.
- Improve User Experience: Offer additional services like logging, caching, and latency reduction.
- Monetize Services: Provide an open marketplace where developers can access AI models with flexible pricing.
How to Run DeepSeek in a Fully Decentralized AI Stack
DeepSeek, an open-source large language model (LLM), can be deployed in a fully decentralized AI stack to eliminate reliance on centralized providers, enhance accessibility, and ensure censorship resistance.
Deploying DeepSeek within a fully decentralized AI stack involves seamlessly integrating decentralized compute, storage, and inference networks to create a robust and censorship-resistant AI pipeline.
This section provides a step-by-step guide on how developers can deploy, store, and query DeepSeek using Akash Network for compute, IPFS/Filecoin for storage, and Pocket Network for decentralized AI inference.
At the end of this process, you will have a fully functional, decentralized Deepseek AI model deployment capable of handling real-world queries without permission and censorship in a cost-efficient manner.
Step 1: Deploying DeepSeek on Akash Network (Compute Layer)
Why Akash for Compute?
Akash Network eliminates vendor lock-in and enables developers to bid on compute power dynamically, making it more cost-efficient than traditional cloud platforms.
Selecting the correct GPU instance before deploying DeepSeek on Akash is crucial, as providers offer varying performance levels, memory sizes, and power consumption.
How to Deploy DeepSeek on Akash
a. Containerize DeepSeek
- DeepSeek must be packaged as a Docker container to ensure compatibility across distributed compute nodes.
- The container should include CUDA, PyTorch, and required dependencies.
dockerfile
FROM nvidia/cuda:12.1-base-ubuntu20.04
RUN apt update && apt install -y python3 python3-pip
COPY deepseek_model /app
WORKDIR /app
CMD ["python3", "run.py"]Reference: Akash’s Containerization Guide
b. Define Compute Resources in Akash’s SDL
Use Akash’s Stack Definition Language (SDL) to specify GPU, RAM, and CPU allocations, ensuring the infrastructure meets the computational needs of large AI models. For high-performance models like DeepSeek, which require multi-GPU configurations for efficient execution, Akash supports scaling across multiple GPUs.
Developers should refer to Akash’s multi-GPU deployment examples to properly configure inference workloads for models that exceed the capacity of a single GPU.
Multi-GPU Example for Akash: Llama-3.1-405B Multi-GPU Deployment
Ensure the network exposure is configured correctly so inference queries can be processed efficiently across multiple GPUs, reducing latency and optimizing throughput.
Reference: Akash SDL Docs
c. Deploy DeepSeek on Akash
- Use Akash CLI to submit the deployment request.
- Monitor bid acceptance to ensure the GPU lease is secured before execution.
Reference: Akash Deployment Overview
d. Monitor Deployment and Logs
Retrieve logs to verify if DeepSeek is running:
- Monitors bid acceptance → Confirms GPU lease before execution.
- Allocates compute resources dynamically → Optimizes cost-efficiency.
Step 2: Storing DeepSeek Model Weights on IPFS (Storage Layer)
Why Use IPFS/Filecoin for AI Model Storage?
AI models depend on fast, distributed, immutable storage to function reliably in decentralized environments. IPFS (InterPlanetary File System) provides a content-addressable, peer-to-peer network where model weights and datasets can be stored and retrieved without reliance on a single entity.
How to Store DeepSeek Model Weights on IPFS
Upload Model Weights to IPFS
- Initialize an IPFS node and upload DeepSeek’s model files.
- Generate a Content Identifier (CID) for future retrieval.
- Follow the steps in IPFS Official Docs.
sh
ipfs init
ipfs daemon
ipfs add -r /app/deepseek_modelRetrieve Model Weights in DeepSeek
- DeepSeek should fetch model weights dynamically from IPFS when it runs on Akash.
- Configure the model to load weights via HTTP retrieval from IPFS.
- Learn more here.
Step 3: Routing AI Inference Queries via Pocket Network (Inference Layer)
Why Pocket Network for AI Inference?
Pocket Network removes single points of failure by distributing AI inference requests across multiple decentralized nodes, making AI models accessible without reliance on corporate-controlled APIs. Read previous sections.
Configuring DeepSeek to Accept AI Queries
DeepSeek must expose an API endpoint on Akash, allowing Pocket Network to route and process AI queries. This setup ensures that inference requests are handled efficiently within the Shannon Beta TestNet using a Relay Miner and PATH Gateway.
Phase One: Set Up a Local DeepSeek R1 Model
Before integrating with Pocket Network, DeepSeek R1—a leading open-weight AI standard—must have a robust inference backend that ensures scalability and efficiency. vLLM on Akash is the preferred choice for high-performance LLM inference, as it supports OpenAI-compatible APIs, making integration seamless with decentralized infrastructure.
Why vLLM?
- Optimized for high-throughput inference, reducing latency in real-time AI interactions.
- Supports OpenAI-standard APIs, ensuring compatibility with developer ecosystems.
- Designed for multi-GPU scalability, allowing efficient execution of large models like DeepSeek R1.
The model should be configured using vLLM’s inference server to prepare for deployment. This ensures requests can be processed via a standardized API format suitable for Pocket Network’s AI relay infrastructure.
Reference: DeepSeek R1 Model Card
Phase Two: Deploy DeepSeek R1 on Akash with an API Endpoint
Once DeepSeek R1 runs locally, it must be deployed on Akash to enable decentralized inference. The deployment should:
- Utilize Akash’s SDL to specify the necessary compute resources, ensuring multi-GPU support if required.
- Configure the deployment to expose the /v1/chat/completions endpoint, adhering to OpenAI’s API specifications.
Phase three: Register DeepSeek as a Service on Pocket Network
To make DeepSeek accessible via Pocket’s decentralized inference network, it must be registered as a service.
- Create a Supplier Node on Shannon Beta TestNet by staking POKT.
- Set up a Relay Miner, which routes requests from Pocket’s Gateway to DeepSeek’s API endpoint.
Stake the supplier with:
sh
poktrolld tx supplier stake-supplier --config /tmp/stake_supplier_config.yaml --from=$SUPPLIER_ADDR $TX_PARAM_FLAGS $NODE_FLAGSPhase Four: Route AI Queries Through Pocket’s Gateway
After deployment and registration, Pocket Network routes AI inference requests dynamically.
- Applications send queries via Pocket’s AI Gateway.
- The Relay Miner processes the request, forwarding it to a DeepSeek R1 instance running on Akash.
- The model retrieves weights from IPFS if needed, processes the request, and returns the response via Pocket’s decentralized network.
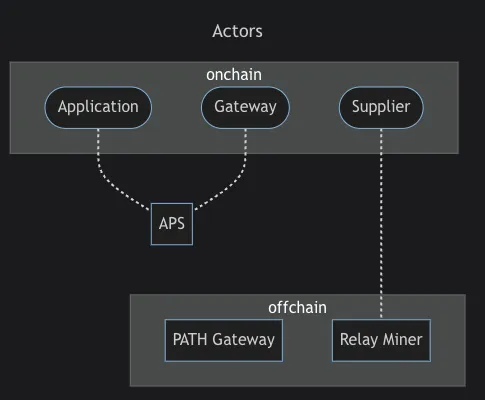
Unifying Compute, Storage, and Inference: How Akash, IPFS, and Pocket Network Work Together
Deploying DeepSeek on Akash, IPFS, and Pocket Network together means:
- DeepSeek runs continuously on a permissionless GPU network (Akash).
- It dynamically loads its model weights from a censorship-resistant storage layer (IPFS).
- AI inference requests are routed and processed without central control (Pocket Network).
How DeepSeek on Akash Connects to the Other Layers
Once DeepSeek is running on Akash, it must:
- Retrieve model weights from IPFS dynamically instead of storing them locally.
- Expose an API that Pocket Network can query for inference requests.
How DeepSeek on Akash Retrieves Model Weights from IPFS
- The DeepSeek instance on Akash fetches its weights dynamically from IPFS using a CID (Content Identifier).
- This ensures that every time a new DeepSeek instance is spun up, it loads the correct model without manual intervention.
How Pocket Network Interacts with Akash & IPFS
- AI requests are sent via Pocket’s API Gateway.
- Pocket routes request to a Relay Miner, which forwards them to DeepSeek’s Akash-hosted API.
- DeepSeek retrieves its model weights from IPFS before processing the request.
- Pocket Network relays the AI-generated response back to the requester.
Call to Action: Build AI on Pocket Network
Pocket Network is redefining AI inference, making it decentralized, scalable, and permissionless. With the Shannon upgrade, developers can deploy AI models like DeepSeek and route queries through a trustless, censorship-resistant network—earning $POKT while ensuring AI remains open.
TLDR:
- Deploy AI on Pocket’s inference layer → Pocket AI Gateway
- Run AI workloads with Akash → Decentralized Compute
- Store model weights securely on IPFS.
Conclusion
The Future of AI Is Decentralized
Deploying DeepSeek across Akash, IPFS, and Pocket Network isn’t just an alternative to centralized AI infrastructure—it’s a paradigm shift. By integrating decentralized compute, censorship-resistant storage, and trustless inference routing, this system removes single points of failure, gatekeeping, and cost barriers that have defined AI accessibility for years.
This is more than just infrastructure; it’s a new foundation for AI development, where models are permissionless, resilient, and accessible to all. This approach ensures that AI remains a decentralized public good, not a corporate-controlled service, whether for autonomous AI agents, on-chain intelligence, or open research.
For developers, this means AI that isn’t just hosted—but owned, accessed, and distributed on a global, trustless network. The tools exist. The infrastructure is ready.