Why Data Ingestion Matters in AI
AI agents in crypto live and die by the blockchain data they consume. Whether it’s a predictive trading bot reacting to mempool surges, an on-chain oracle feeding real-time price ticks to a DeFi protocol, or an AI service that generates dynamic NFT artwork from the latest block events, your AI’s accuracy and speed hinge on how, and how reliably, you pull that data in. Nail your ingestion pipeline, and your AI stays sharp and responsive; miss the mark, and you’re stuck with stale data, slow decisions, or failed trades.
Today, most crypto–AI systems still lean on centralized infra, private RPC nodes, and AI APIs hosted in corporate clouds. They’re fast and reliable, but you need special permissions, API keys, and trust that the provider won’t throttle or censor your access.
A new alternative is emerging: decentralized data ingestion built on networks like Pocket for permissionless data access so your blockchain AI agents can stay autonomous, transparent, and censorship-resistant.
But decentralization isn’t a silver bullet; it has its own quirks to iron out. Let’s dive deep into why data ingestion makes or breaks your blockchain AI, compare the centralized and decentralized approaches, show you how protocols like Pocket Network are changing the game, and share tips to build a rock-solid pipeline without the usual headaches.
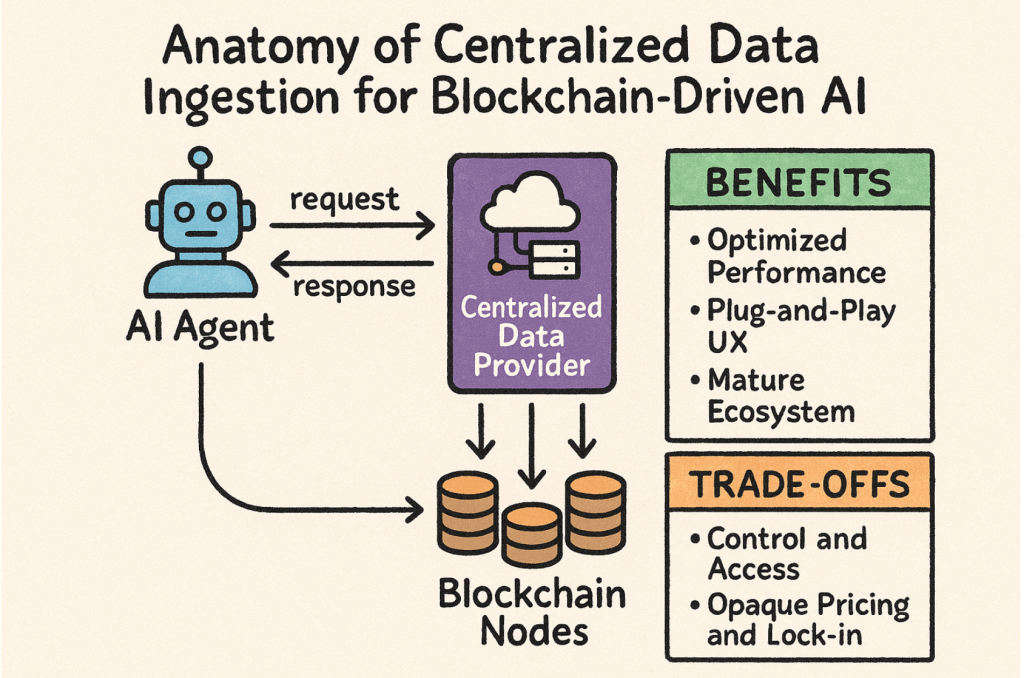
Anatomy of Centralized Data Ingestion for Blockchain-Driven AI
Centralized data ingestion consolidates all steps – data collection, processing, storage, and analysis – into a single data warehouse or lake.
In most blockchain-AI systems today, your agent doesn’t query fifty Ethereum full nodes directly—instead, it leans on a centralized data provider (Infura, Alchemy, QuickNode, etc.). You send a request (e.g., “get the latest ETH block,” “fetch Uniswap V3 swap events”), wait for their JSON-RPC response, and then feed that payload into your LLM or decision-making agent.
This approach has clear advantages:
- Optimized Performance
Centralized providers run fleets of geo-distributed, bare-metal or Kubernetes-backed full & archive nodes. They manage peering, read/write caches, auto-failover, and load balancing so you see sub-100 ms block confirmations and thousands of requests per second—without spinning up or maintaining any infra yourself. - Plug-and-Play UX
One API key (or HTTPS endpoint) unlocks every chain they support—Ethereum, BNB Chain, Arbitrum, Polygon, Solana, Avalanche, you name it: no CLI spin-up, no staking deposit, no multi-gigabyte node sync. - Mature Ecosystem
Hosted on AWS, GCP, or Azure with built-in dashboards for usage analytics, error alerts, SSO/role-based access, and contractual SLAs. You get per-month or pay-as-you-go billing, logs, and enterprise support out of the box.
But these benefits come with deep trade-offs:
- The provider alone decides which chains, archive depths, and RPC methods you can use so that advanced calls may be unavailable or overpriced.
- Pricing is opaque and vendor-specific, with steep mark-ups for archive queries and costly endpoint rewrites if you switch providers.
- Centralized gateways can throttle addresses, block contract calls, or suspend accounts at will, instantly cutting off your data feed.
- You get no visibility into node lag, reorg handling, or cache rules, so stale or inconsistent data can slip into your model without an audit trail.
How centralized data ingestion works for blockchain AI
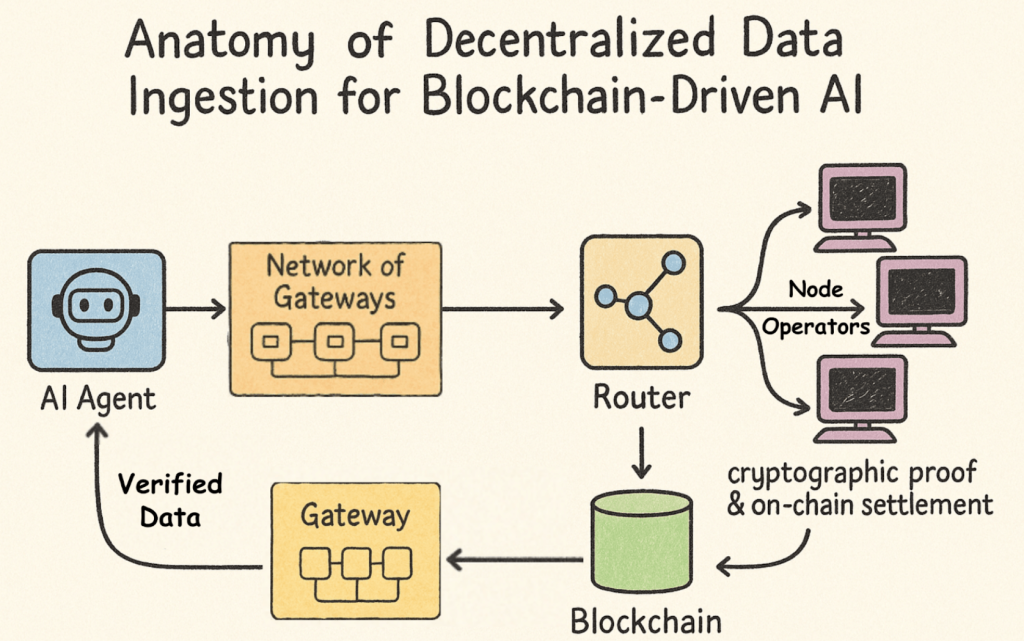
Anatomy of Decentralized Data Ingestion for Blockchain-Driven AI
All right, now let’s flip the script and see what a truly decentralized pipeline looks like. Imagine your AI agent pulling data not from a single corporate gateway but from a permissionless, open-economy network—where every piece of the stack is verifiable on-chain, transparent, and resistant to censorship. Here’s the high-level breakdown:
Definition
Decentralized data ingestion means your AI agent pulls on-chain information via an open, permissionless mesh of gateways and node operators rather than through a single corporate API. Anyone can run a gateway, stake tokens, and earn rewards by serving data, yet all requests and payments remain transparent and auditable on the blockchain.
How It Works (Overview)
When your AI needs on-chain context, say, the latest block number or a smart-contract state, it broadcasts a standard JSON-RPC call to any gateway in the network. That gateway relays the request across a pool of independently operated full-node providers, each competing based on reliability and performance.
The chosen node executes the query and returns the raw data, while the gateway records a cryptographic proof of service on-chain and settles tokens exactly for the compute used. Finally, the verified response arrives back at your AI, ready for immediate inference.
Key Benefits
- Permissionless Access: No API keys, no whitelists, anyone can join as a gateway or node operator.
- Transparent Economics: Every relay, proof, and token payment is visible on-chain, so you only pay for what you consume.
- Censorship Resistance: With no central bottleneck, no single party can throttle, delist, or shut down your AI’s data feed.
- Unified Multi-Chain Support: One protocol spans dozens of blockchains—Ethereum, rollups, testnets—without juggling separate endpoints.
Trade-Offs & Considerations
Decentralization does bring a bit more setup overhead; you’ll need to choose or deploy a gateway endpoint and handle occasional on-chain interactions. Response times may vary more than with a dedicated, centrally managed cluster, and each proof of service carries a small on-chain fee. Still, for AI agents demanding true autonomy, auditability, and resilience, these modest trade-offs often pale next to the benefits of a fully open, stake-backed ingestion layer.
Anatomy of Decentralized Data Ingestion for Blockchain AI
Architectural Comparison: Centralized vs. Decentralized AI Ingestion
Here’s a snapshot of the core trade-offs when you compare a single-provider pipeline to an open, mesh-driven one:
| Feature | Centralized Ingestion | Decentralized Ingestion |
| Control | Provider-owned | User-sovereign |
| Access | Gated APIs | Permissionless |
| Cost Transparency | Opaque tiers, token-based | Deterministic per-relay (CUs) |
| Scalability | Limited; bottlenecks under high traffic | High; handles growing demand effectively |
| Fault Tolerance | Single point of failure | Isolates issues to specific nodes |
| Latency | Higher due to centralized processing | Lower via parallel/local routing |
| Redundancy | Single provider | Multi-node routing |
| Infrastructure Cost | Higher; centralized resources | Lower; distributed load reduces costs |
| Security | Vulnerable; single point of attack | Distributed; reduces the impact of breaches |
| Model Diversity | Curated selection | Long-tail open-source models |
| Data Sovereignty | Provider logs usage | Privacy-first, audit on-chain |
Pocket Network’s approach leverages Compute Units (CUs) as a universal pricing primitive—1 billion CUs = USD 1, so your AI spends exactly what it uses, whether you’re fetching Ethereum blocks, Polygon state, or even LLM inferences. This CU model brings crystal-clear billing across chains and services, fully visible on-chain.
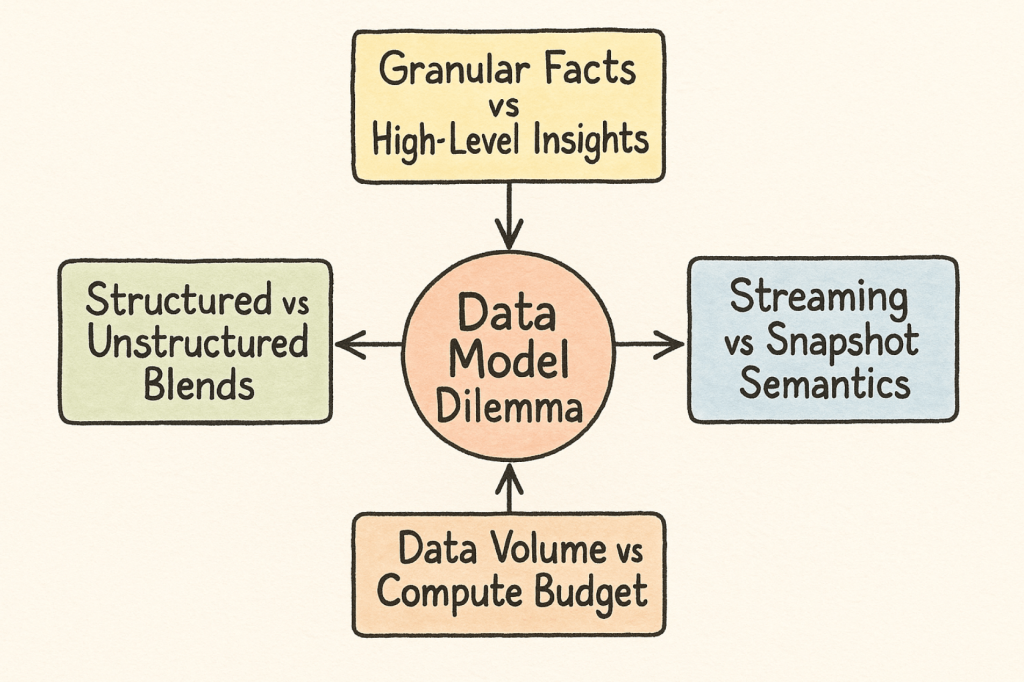
The Data Model Dilemma
Every choice in a blockchain-AI pipeline—what you sample, how you store it, and when you serve it—shapes your model’s accuracy, cost, and responsiveness. Centralized APIs force you into one rigid schema, while decentralized networks offer on-the-fly flexibility at the expense of new complexities.
Here are the four core tensions you’ll wrestle with when turning raw on-chain data into AI-ready inputs:
- Granular Facts vs. High-Level Insights
Blockchains record every transaction and event in detail, but AI often needs aggregated views—“net flows over the last hour” or “whale activity patterns”—rather than byte-perfect logs. - Streaming vs. Snapshot Semantics
Ingesting every new block or mempool change gives you full fidelity (at high cost), whereas periodic snapshots simplify processing but can miss flash-loan attacks or sudden network shifts. - Data Volume vs. Compute Budget
Full-archive nodes hold terabytes of history—ideal for precision but expensive to query—while trimmed or cached datasets save on compute (and CUs) but risk hiding rare, high-value anomalies. - Structured vs. Unstructured Blends
On-chain logs are neatly typed, yet real insight often comes from joining them with messy off-chain feeds—price oracles, social sentiment, NFT metadata—requiring adaptive schemas and robust validation.
Data Model Dilemma For Blockchain Agents
Aligning with Blockchain Ethos: Why Decentralized Ingestion Is Your Go-To Toolkit
When your AI or dApp fetches blockchain data, the interface you choose either honors decentralization or undermines it. Native tools such as JSON-RPC (EIP-1474), event logs, Merkle-proof state queries, and peer-to-peer streams are permissionless, verifiable, and censorship-resistant. Centralized gateways, by contrast, hide those primitives behind proprietary APIs, opaque caches, and black-box routing, reintroducing a single point of control.
A truly decentralized pipeline preserves the chain’s openness and adds real accountability: every gateway and node operator stakes tokens as collateral, so poor uptime or bad data carries on-chain penalties. Want to add an archive node, a mempool indexer, or a new Layer-2? Just spin it up, stake, and plug in—no vendor approvals or waiting lists.
Best of all, every request and payment writes an immutable proof to the ledger. Auditors, regulators, or your own monitors can replay calls and confirm exactly what was served. And because dozens or hundreds of peers stand ready, there’s no bottleneck to throttle, deplatform, or censor your AI’s data feed.
Decentralized ingestion keeps your data path as open, trustworthy, and unstoppable as the blockchain itself.
Effects on AI Systems
Speed & Scale
Decentralized load-balancing spreads requests across thousands of nodes, eliminating the bottlenecks that plague centralized pipelines. Pocket Network, for instance, routes ≈1 trillion relays through 10,000+ nodes without a dip in performance—keeping latency low even at peak demand, streaming from many sources at once, and flexing capacity on the fly.
Resource & Risk Profile
Centralized stacks demand meticulous capacity planning and crumble at single points of failure. A distributed mesh shares the load automatically, slashes over-provisioning costs, and self-heals if any node falters. The DeepSeek deployment on Pocket Network proved the point, running uninterrupted while managing resources transparently.
Implementing Decentralized Data Systems – Pocket Network in Production
How a permissionless RPC mesh keeps a live AI agent fed, fast, and verifiable
Pocket Network’s Shannon-era stack is the first end-to-end demonstration that fully on-chain economics, open gateways, and multi-node routing can serve real AI workloads at scale—without leaning on a central cloud. Below is a ground-level look at what actually happens when an LLM-powered agent consumes blockchain data through Pocket.
Pocket Network is already one of the largest decentralized data backbones on the public internet, and particularly, the 2025 Shannon upgrade has enhanced its capabilities to handle AI workloads.
| Actor | Real-world role | Why it matters for AI ingestion |
| PATH Gateway | A lightweight HTTP/WS facade you can self-host | Turn any JSON-RPC call from your model into a signed, stake-backed relay request. |
| RelayMiner | Off-chain “switchboard” | Picks the best Supplier, assembles proof-of-work, and posts it to the chain. |
| Supplier Node | Full or archive node run by an independent operator | Executes the query; earns POKT only if the proof checks out. |
An Example Live Query Routed Through Pocket Network
Below, we walk through the identical mechanics from the viewpoint of a traditional blockchain application (DEX dashboard, trading bot, wallet tracker, etc.)
- App → Gateway: The dApp fires a JSON-RPC call—“trace_block <latest-3600s>” against Base Mainnet. The PATH Gateway detects the service-ID (base), computes the CU cost, signs with its staked key, and queues the relay.
- Gateway → RelayMiner: The RelayMiner consults on-chain performance metrics (latency, error streaks, archival depth) and selects the highest-ranked Supplier for Base.
- Supplier → RelayMiner: The chosen node returns the block-trace payload. The miner concatenates hash(request)‖hash(response)‖SupplierPubKey, produces a relay proof, and hands it to the Gateway.
- On-chain Metering & Settlement: The Gateway submits the proof to the Shannon chain. Exactly the number of CU priced for that trace call are burned from the Gateway’s balance, while the Supplier and Validator set receive freshly minted POKT. (The Shannon upgrade overhauls Pocket’s tokenomics, pegging every request to a precisely priced compute-unit so costs now reflect exact, real-time usage.)
- Gateway → App: The verified result streams back to the dApp UI. From trigger to render, the call is cryptographically auditable, economically settled, and free of single-provider lock-in—yet the developer wrote nothing beyond a standard RPC request.
Yes — the same relay flow also serves AI chatbots. Grove’s May 2025 demo shows a DeepSeek-powered LLM sending prompts through a PATH gateway and getting on-chain answers in real time. The only thing that changes for an AI agent is the code that consumes the JSON-RPC response.
Resources & Next Steps for Builders
Over the past few sections, we’ve seen why decentralized data-ingestion is critical for any AI that draws insight from blockchains and how Pocket Network’s Shannon upgrade turns that principle into production-ready infrastructure. Shannon provides the tooling, on-chain proofs, and stake-backed incentives to make it happen. If you’re ready to jump in, start with the resources below.
- PATH Gateway Operator
- Blog: How PATH Saves You on RPC Costs and How to Run It → Blog Link
- Quick Start Guide: Set up PATH in 10 minutes → Guide
- Deep Dive: Helm & Kubernetes Deployment Guide → Grove Doc’s Link
- Relay Miner
- Blog: All Aboutz/ Relay Mining on Pocet Network → Blog Link
- Deep Dive: Supplier & RelayMiner Cheat Sheet → Pocket Network Dev Docs
- Node Supplier
- Quick-Start: Full Node Cheat Sheet → Docs Guide Link
- Deep Dive: Full Node – Binary → Pocket Network Dev Docs
- Data Source / AI Model Host
Other Sources: Pocket Network Developers Docs
Whether you’re building a gateway, running a Relay Miner, staking nodes, hosting data, or simply switching your dApp to Pocket Network’s permissionless RPC mesh, there’s no better time to jump in.
Choose the role that best matches your objectives, follow the Quick-Start documentation, and you’ll have your first on-chain proof settling in minutes. If questions arise, our dedicated Discord channels (#gateway-builders, #relay-miners, #node-ops, #data-sources, #dev-help) provide real-time guidance and a place to share progress with peers.
Start building today and empower your AI or Web3 project with a data pipeline that is fully decentralized, transparent, and censorship-resistant.
Jump In
Blockchain-driven AI deserves infrastructure that is as open, auditable, and resilient as the chains it studies. Decentralized data ingestion delivers exactly that—turning every query into a verifiable on-chain event and every node into a partner, not a gatekeeper. With Pocket Network’s Shannon upgrade, those capabilities are no longer theoretical; they’re live, production-ready, and only a few clicks away.
Whether you’re training models, powering autonomous agents, or simply future-proofing a dApp, now is the moment to leave centralized bottlenecks behind and build on a foundation that scales with the ethos of Web3. The tools are here, the routes are permissionless—let’s redefine what AI can do when its data is truly decentralized.