
Redundancy isn’t the same as reliability. The gap is your front door for data. Read on for a comparison of single-cloud, multi-cloud, and decentralized cloud environments – with Pocket Network’s Decentralized Access Layer as a reference.
Prologue: The day redundancy didn’t save the launch
The launch window was tight. A new pricing page, a refreshed onboarding flow, and several analytics experiments were queued up behind a feature flag. Traffic began to increase as marketing bids took effect. Two minutes later, the latency charts showed a lopsided spike; reads were fine in one region, but wobbly in the other—a few requests timed out, followed by a few more. The incident channel woke up.
This wasn’t supposed to happen. The architecture was “multi-cloud,” complete with duplicated services, extra dashboards, and diligent on-call rotations. Yet the team still had to decide—fast—what traffic to shift, which vendor to trust, and how to keep the analytics pipeline from polluting the dashboards with partial data.
After the fix and a long exhale, one statement lingered among the team: “We had redundancy, but not a reliable way to choose the good path in real time.” That statement is the heartbeat of this post. If you’ve built multi-cloud and still end up negotiating with the outage gods, the missing piece is not “more cloud.” It’s decentralized data access—a neutral access layer that routes requests across multiple suppliers, filters out inadequate responses before they reach your app, and leaves a verifiable record for every request.
Most teams already try to solve that problem in one of three ways.
The Three Main Paths to Reliability
Every engineering team faces the same question sooner or later: how do we keep things running when the unexpected happens? There are three common paths that companies take—each with its strengths, tradeoffs, and hidden costs.
The first two are well understood: single cloud and multi-cloud. The third, newer path—decentralized data access—is what turns redundancy into absolute reliability.
1. Single Cloud
This is where most teams start. You pick one provider, learn its tools, and build around its ecosystem. It’s clean, predictable, and easy to manage. One bill. One dashboard. One support contract.
The tradeoff is also simple: a single point of failure. When that region or vendor experiences a problem, so do you. We saw last month, when AWS’s US-EAST-1 region went down and disrupted services across the internet, from major apps to small APIs that quietly depended on it.
2. Multi-Cloud
Adding another provider seems like the logical fix. It spreads workloads across vendors and regions, providing redundancy if one vendor or region fails. In theory, that means better uptime and flexibility.
In practice, multi-cloud replaces dependency risk with complexity risk. Each platform has its own monitoring, networking, and billing logic. Teams end up managing two of everything: alerts, SLAs, and even mental models.
3. Decentralized Data Access (DAL)
A decentralized access layer approaches the problem in a different way. Instead of running separate stacks and deciding which one to trust during a failure, it builds a neutral front door—a single point where all data requests pass through.
The layer continuously measures which routes are healthy, automatically sends each request to the best performer, and drops slow or inconsistent responses.
Where Multicloud Struggles
Multicloud sounds excellent on paper, suggesting resilience, flexibility, and freedom from vendor lock-in. However, in practice, issues quickly arise—during incidents, when reviewing cloud bills, and when teams need to uncover the truth about what happened, as well as in other scenarios.
Across recent outage reports, research, and industry surveys, a pattern keeps repeating: multicloud solves one set of problems by quietly creating another in these areas:.
a) Decision lag during incidents
Redundancy gives you options, but it doesn’t make decisions. When a region wavers, humans still decide when/where to shift traffic. The October 2025 AWS US-EAST-1 outage made that clear; redundancy doesn’t automatically translate to responsiveness.
b) Fragmented observability across vendors
Logs, traces, and metrics live in different tools per provider. Putting it all together under pressure becomes a matter of guesswork. It’s why the CNCF’s latest survey lists cross-cloud observability as one of the top operational pain points in cloud-native systems.
c) Cost creep (egress + duplication)
Data doesn’t move for free. Every transfer between providers incurs egress fees, and every standby environment incurs additional costs for capacity. Over time, those “safety buffers” start to blur forecasts and quietly eat into margins. Cloudflare’s data egress reports have long shown that egress is one of the most challenging costs to predict or contain in a multicloud world.
d) Operational complexity that scales with every new provider
Every additional cloud brings its own SLAs, quotas, IAM models, and failure patterns. Flexera’s 2025 State of the Cloud Report notes that while most enterprises now run workloads across three or more providers, they also report an increasing burden of data governance overhead and skill shortages in managing them.
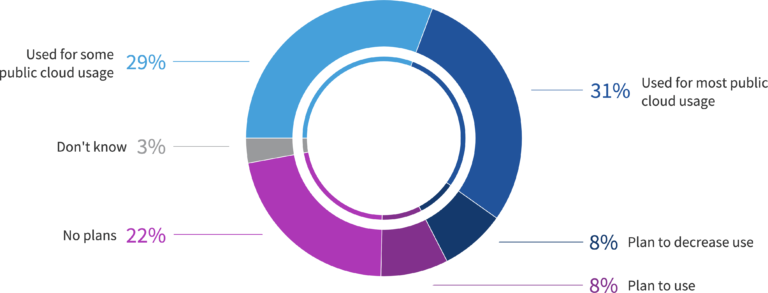
Utilization of MSPs for managing public cloud for all organizations. Source: Flexera
e) Unpredictable cloud spend, even with FinOps
FinOps frameworks help, but they don’t change the fundamentals: more providers mean more SKUs, contracts, and hidden fees. Surveys indicate that over 90% of organizations continue to struggle with achieving clear visibility into their total cloud spend.
How decentralized data access actually delivers reliability
Reliability is more than just having backups; it’s about making the right choice for every request and being able to prove it. The following section explains how this model integrates into modern stacks and the benefits teams experience daily.
How a DAL fits your stack
A decentralized access layer shows up in two practical ways. As an overlay, it sits in front of what you already run and acts as the control point for policy and routing. As a platform, it’s the data access fabric itself with one network, many independent suppliers, and verifiable records by default. Both patterns keep your apps talking to a single endpoint while moving decisions and accountability to the front door.
- Overlay: You expose one endpoint, set latency/error/freshness policies, and let the layer steer only to healthy backends. To roll out an update, mirror a small slice of read traffic, compare results, then scale or swap back by changing the endpoint. This model is standard in Web2, where checking health at the edge is a standard practice for load balancing.
- Platform (complete decentralized fabric). In Web3, a DAL can serve as the access network, rather than a thin proxy. Your apps call one gateway, behind it, independent suppliers (node operators) compete to serve each request. Routing and quality checks run continuously, and each call leaves a receipt you can verify. For example, Pocket Network utilizes PATH gateways at the edge, backed by a marketplace of suppliers.
The Value of a Decentralized Access Layer
Making quicker, more informed decisions is crucial, and having a reliable record of those decisions is equally essential. A decentralized access layer (DAL) effectively provides both. Other values that a DAL offers include:
Real-time routing, not war-room guesswork
A proper DAL watches live health, including latency, availability, freshness, and routes each request to the best supplier at that moment. For example, Lava Network decentralized RPC pairs clients with node providers using QoS scores that directly affect who’s eligible to serve and get paid.
Quality gates at the front door
Reliability is more than just picking a path; it’s keeping bad responses out. Pocket Network, a decentralized data access protocol, for example, enforces QoS and relay-proof checks at the gateway, discarding slow/invalid replies before they reach your app, and ties supplier rewards to validated delivery. In practice, the “front door” makes the decision, and the proof makes it accountable, which is why incidents shrink from user-visible outages to quiet reroutes.
Receipts you can audit
A DAL should leave a tamper-evident record for every call. Information such as who served it, what policy applied, and whether a retry or hedge occurred should be preserved so that finance, security, and auditors can verify delivery without needing to reconcile vendor logs. For example, in The Graph, a decentralized query access network, payments are attached to requests and responses are returned with validity proofs via state channels.
Additive by design
A DAL sits in front of what you already run, allowing teams to mirror a small slice of traffic, compare latency/errors/receipts, and then scale without requiring schema rewrite or a rip-and-replace approach. For example, Pocket Network exposes a single gateway endpoint you can operate yourself with PATH or consume as a hosted endpoint.
Web2 access layers that feel like a DAL (and what’s missing)
Big enterprises already use Web2 tools that resemble a decentralized access layer for data. Cloudflare Load Balancing provides a single entry point, directing traffic through active health checks and pooled origins. IBM NS1 Connect (Pulsar) provides real-user-measurement steering, enabling the selection of the best CDN or endpoint in real-time. Scality Zenko presents a single S3-compatible namespace across multiple object stores, handling cross-cloud replication and policy from a single controller.
Where they fall short is in decentralization (permissionless entry) and proof. These systems centralize the control plane with a single vendor. While you receive logs and dashboards, you typically don’t get tamper-evident, per-request receipts that accompany the data across suppliers.
A proper decentralized data access layer maintains the same front-door simplicity. Still, it fills the gaps with a permissionless supplier set, cryptographic receipts tied to each request, and consistent unit pricing across providers.
Pocket Network as a Decentralized Access Layer
Pocket Network is a decentralized access layer that you can place in front of your existing endpoints/apps, built from clear components that work together as one cohesive system. It implements the DAL model for blockchain and adjacent data.
The technical architecture of Pocket Network, as a decentralized data access layer, is complex and broken down as follows:
- PATH gateways sit at the edge to handle policy, identity, and quality checks.
- Relay Miners provide the network’s control plane, maintaining the live health of suppliers and packaging each served call into a verifiable relay proof.
- Suppliers (independent node operators) run registered services for different data endpoints on Pocket Network.
- Validators and the protocol account manage usage in compute units, including on-chain burn, rewards, and DAO-set economics such as rebates and pricing guards.
Taken together, these components provide a single endpoint to call, backed by supplier diversity, cryptographic receipts that your finance and security teams can trust, and unit economics that map cleanly to “per-request” consumption.
It’s built for Web3 today and designed to integrate with Web2 data sources without modifying how your apps interact with an API—keeping your stack intact while moving decision-making, assurance, and incentives into the access layer.
Pocket Network data served
Pocket Network serves a wide range of data, spanning multiple specs and use cases across industries. Below is a list of the available data categories in Pocket Network, which are continually expanding, so you can easily map them to your workloads.
- Multi-chain blockchain RPC, read and write calls including archival history across EVM and select CometBFT networks, JSON-RPC and WebSocket supported.
- Indexing and query APIs, subgraphs and custom REST/GraphQL endpoints published as Services behind a PATH gateway.
- AI inference endpoints, open-weight models exposed behind the gateway with eligibility and delivery tied to network proofs.
- Verifiable usage records, per-request relay proofs and QoS metadata suitable for audit, chargeback, and supplier settlement.
- Expanding surface for new data, suppliers can register other API-style services today, and the roadmap includes broader data types as Shannon pricing generalizes via compute units.
For more information, you can explore available live services, suppliers, and network stats on the Pocket Network explorer, PoktScan.
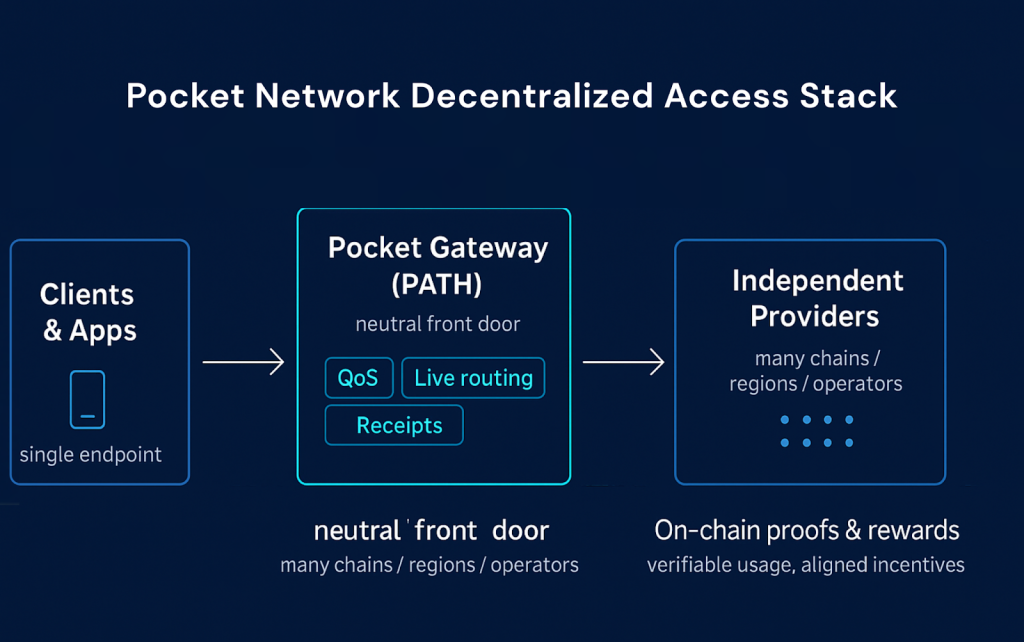
Pocket Network Decentralized Access Stack
Multi-cloud vs. a Decentralized Access Layer — what teams experience
We’ve outlined how a DAL fits and how Pocket implements it. Now let’s put it next to multi-cloud and compare what teams actually feel in production—during incidents, in budgeting, and at audit time. To keep this practical, instead of listing features, we’ll focus on the outcomes—what a team actually experiences when things go sideways.
| Outcome | Multi-cloud | Decentralized data access |
| During a wobble | Humans weigh dashboards and runbooks; partial fixes first | Traffic shifts to healthy suppliers automatically; bad responses are filtered |
| Cost behavior | Duplication, egress, and idle failover blur forecasts | Unit-based metering keeps costs comparable and forecastable |
| Evidence | Logs are fragmented across vendors | Per-request receipts create one verifiable ledger |
| Ops effort | More clouds mean more runbooks and dashboards | One front door reduces interventions and simplifies cutovers |
| Global performance | Re-implement per provider and region | Route by live health and geography; scale horizontally |
| Risk concentration | Lower than single cloud, still decision-heavy | Lower and decision-light; “best path now” becomes the default |
| Audit and compliance | Reconciliation across sources takes time | One canonical trail speeds audits and chargebacks |
| Change management | Vendor or region shifts touch many systems | Policy and endpoint updates handle most shifts |

Single Cloud Vs MultiCloud Vs Decentralized Access Layer
Multi-cloud spreads risk; a DAL turns routing and proof into default behavior, making reliability, costs, and audits easier to manage.
How to ensure security, risk and compliance in a decentralized data access infrastructure
This section keeps it practical: how to tell if your implemented decentralized access layer is working perfectly. Security encompasses two key aspects: prevention and provability. Teams often nail the first and struggle with the second. An access layer that emits per-request receipts gives you provability as a feature of everyday operation, not a special project during audit season.
- Evidence on demand. You can precisely identify which supplier provided which data at a specific time. No more reconciling uneven logs or guessing at sequence.
- Reduced blast radius. Supplier diversity is built in. If any provider drifts out of spec, routing drops traffic before your app feels the pain.
- Clarity on data handling. Good access layers make it obvious what’s logged, how it’s stored, who can see it, and how incidents are disclosed.
Five questions to ask any access layer:
- What exactly is recorded per request, and how is it tamper-evident?
- How do you filter or reject slow, stale, or invalid responses?
- How is data protected in transit and at rest (for logs and receipts)?
- How do you verify supplier identity and performance?
Closing thoughts
Multi-cloud helped the industry grow past single points of failure. But redundancy alone won’t choose wisely on your worst day. Decentralized data access does the choosing, explains itself with receipts, and gives you pricing you can plan around. It doesn’t ask you to switch clouds or rewrite your app. It replaces panic with posture.
Start in shadow. Prove parity. Move a slice. If your charts get quieter and your scorecard looks boring, you’ll know you’ve traded a pile of options for a simple habit: one front door, many healthy paths.
What to do next
- Pick one path and baseline. Choose a read-heavy endpoint: record p50/p95 latency, error rate, and cost per million calls for a week.
- Mirror a small slice. Send 10% through the DAL during a change window you already trust. Confirm response parity. Tune simple policies (latency, errors, freshness).
- Step up, then score it. Raise to 25–50% in business hours—export receipts. Fill the outcome sheet: uptime, cost predictability, audit trail, vendor management, global performance, and ops overhead.
- Decide and deploy. Expand by endpoint if it wins. Roll back by swapping the URL if it doesn’t.
- Choose your ops model. Self-host a gateway for control, or use a managed option to move faster. Pick the one that fits your team.